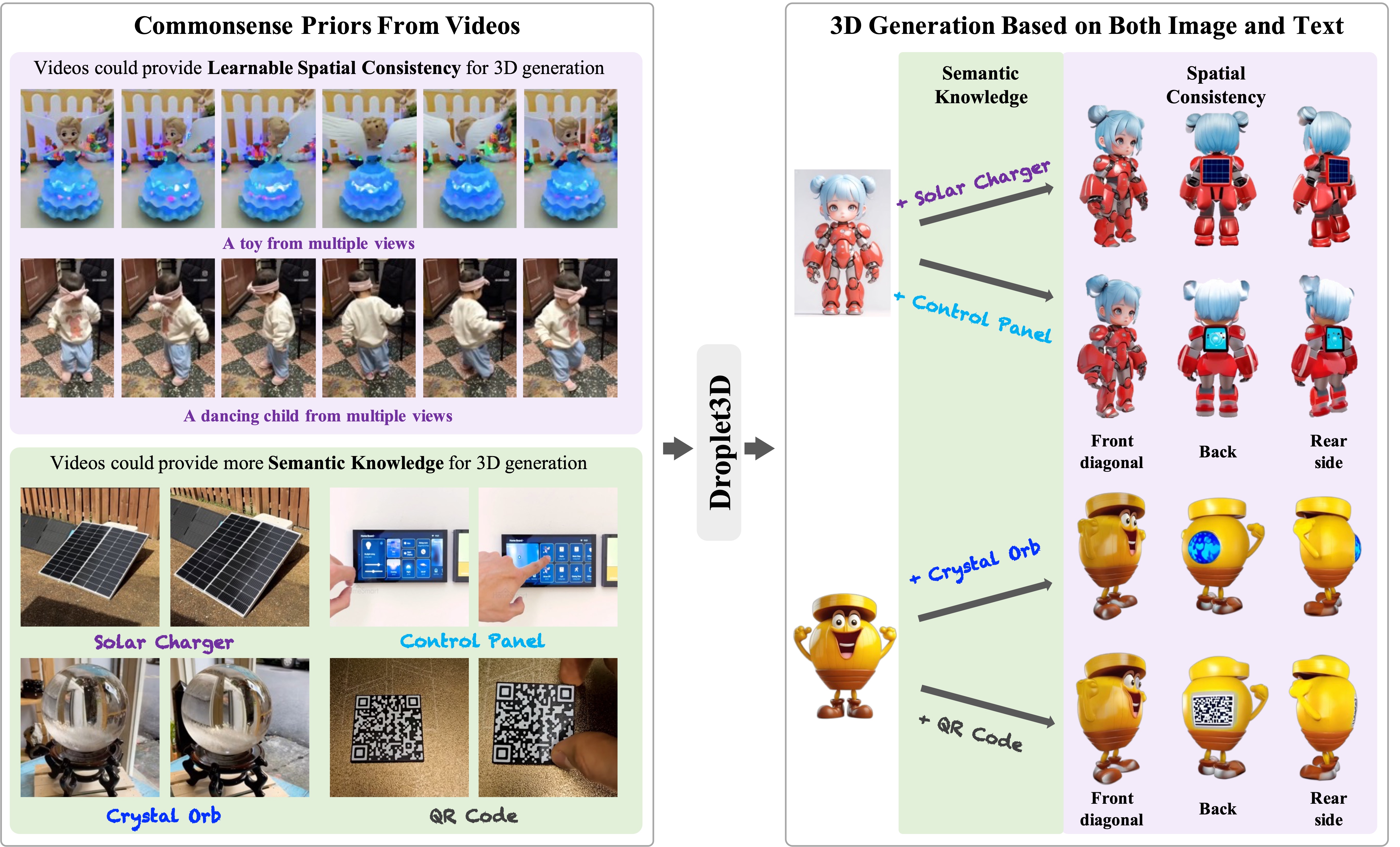
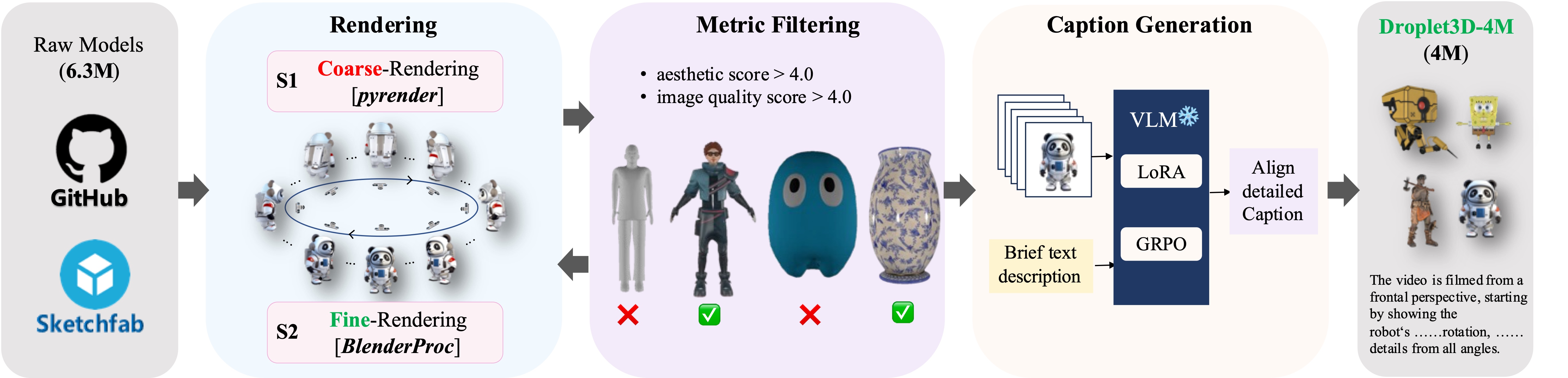
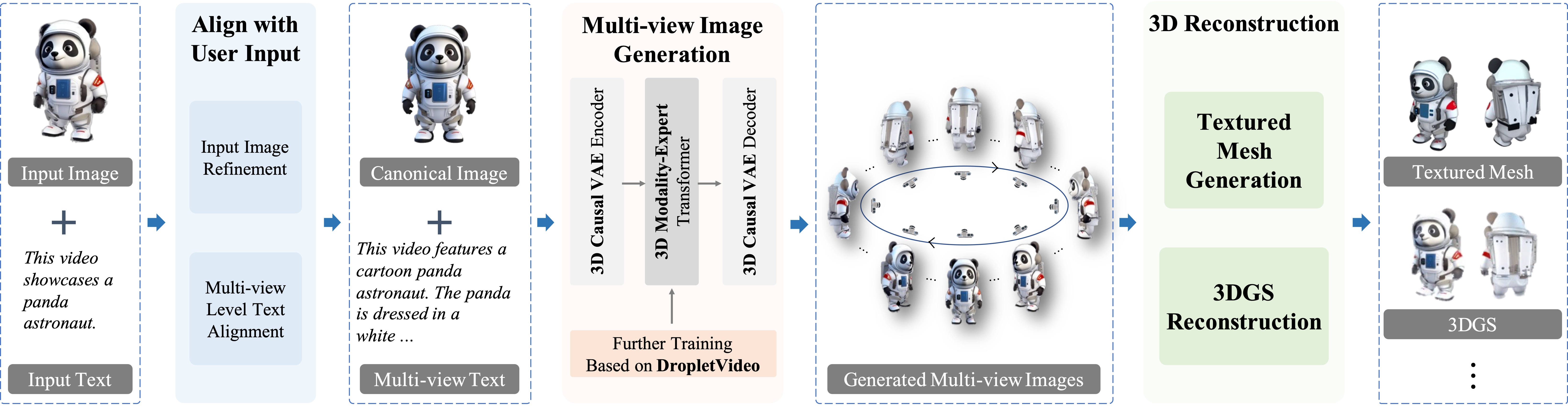
To validate the accuracy of the generated content by Droplet3D given a single image and text prompt, we compared it with other TI-to-3D methods, including LGM, Hunyuan3D-2, MVControl, and TRELLIS.
Example 1
This character is an anthropomorphic onion figure. The main body is bright yellow, with a round cap on top. The body is segmented, with a smooth and plump texture, and features vertical stripes. The character has a wide, open-mouthed smile, white eyes with black pupils, and the facial features are concentrated at the front. It has short, stubby arms and legs, and wears brown round-toed boots. The overall proportions are exaggerated and the style is consistent, exhibiting distinct characteristics of a cartoon toy.
The video begins with a front view of the onion character. The camera then slowly moves around to the side, revealing the round outline of the cap and the parallel contour lines of the onion body’s texture. As the camera gradually shifts to the back, the surface texture of the onion is shown to be symmetrical and continuous, and the edge of the cap is even and smooth. The camera continues to move to the other side, eventually returning to the front view, where the round cap on top and the shiny boots below visually echo each other, further highlighting the character’s cute, cartoonish style. After a full rotation, the video ends, leaving a deep impression of the character’s overall roundness and bright colors.
Example 2
The image presents a fantastical scene rich in Eastern ambience. The main subject is a traditional multi-story pagoda, perched atop a steep rocky island peak. The pagoda has a complex structure, dominated by dark red and brown tones. Its roofs curve upwards and ascend in tiers, crowned with a golden spire, which gives it a majestic and mysterious appearance. Mist and clouds swirl around, creating a visual illusion of floating in mid-air, making the pagoda seem as if it is suspended above the sky. The island is covered with vibrant red-leaved trees, which complement the red sky in the background, creating an atmosphere that is both warm and solemn.
As the camera circles around the pagoda, the various angles of the structure and changes in the environment can be observed. The front view displays the pagoda's complete edges and eaves, with strong colors making it stand out even more against the red background. From the side, the layered structure of the pagoda is evident. Circling to the back, the suspended pillars between the pagoda's sections appear like paths leading to unsolved mysteries, and the red trees are even denser from this angle. Finally, the camera returns to its initial position, once again revealing the full view of the pagoda and the stunning visual impact brought by the red sky.
Example 3
The cute girl is dressed in a red mech suit, carrying a heavy red mechanical backpack. She stands upright with her chest out and head held high. The mech suit is mainly a vibrant red, while her hair is blue, styled into a bun with short hair neatly parted down the middle at the back of her head. Her torso is equipped with red armor, and the joints near the red armor on her shoulders, chest, and knees are connected with silvery metallic parts. On her back, there is a heavy red mech backpack that gleams with a metallic sheen.
The audience first sees the robot from the front, with her facial expression clearly visible. Then, as the view rotates to the side, the girl can be seen standing straight with her head held high, her head rounded and her nose slightly upturned. The joints connecting her arm and leg armor are silver, framed by red protective gear, and the center of the shoulder armor features a silver circle. As the rotation continues, the back armor can be observed, revealing the complete red back armor. Finally, the view continues to rotate until a full circle is completed.
Example 4
The image depicts a cute little girl in a minimalist style, standing upright and giving off a sense of warmth and tranquility. She has smooth, light blonde hair that falls just below her shoulders in soft waves. A pink flower adorns her hair, adding a touch of gentleness and innocence. The girl has delicate features and a sweet expression. She is wearing a loose, light beige long-sleeve sweater, with a slightly longer hem for a casual and natural look. She holds a brown book in both hands, with simple letters on the cover. She is wearing light-colored split-toe cotton socks and no shoes.
The viewpoint starts from the front and then rotates; throughout the process, the girl's posture and smile remain unchanged. As the camera moves to the side, the softness and natural flow of her hair become more apparent, showing its gentle waves and length just past her shoulders. Rotating to the back, the length of her hair at the back matches what is seen from the side. When the camera returns to the front, the letters on the cover of the book in the girl's hands are clearly visible. The entire video presents a multi-angle close-up of this lovely girl, always maintaining her pure and warm aura.
Example 5
A cartoon panda astronaut with a round face and classic black and white color scheme, wearing a finely crafted white spacesuit with a blue control panel and wiring on the chest, red badge decorations on the shoulders, black gloves, and white boots, continuing the classic color scheme. The overall design is casual and friendly, showcasing a space exploration image.
The video begins with a eye-level perspective, first showing the panda astronaut's front view, from which the smile and the front details of the spacesuit can be observed. As the video continues to rotate, the side view is revealed, making the panda’s round ears and the spacesuit’s backpack structure more prominent. As the panda continues to turn on the screen, the back view gradually appears, showing the equipment and vest design on the back. Finally, the panda completes a 360-degree rotation, giving the audience a full-body view before the video ends. Each angle showcases a different charm of the panda astronaut, making the presentation delightful and full of imagination.
Example 6
A multi-layered tower house in a magical fairy tale style, with a colorful mottled tile roof, vines entwined around the exterior walls, a chimney and hanging lanterns on the tower top, warm yellow light emanating from the windows, and a cobblestone path leading to the door, with colorful mushrooms and green plants scattered around.
The camera maintains a steady height while smoothly performing a 360-degree horizontal rotation around the fairytale house. It begins by showcasing the main architectural features of the front facade. As the camera moves to the side, numerous windows come into view. When it reaches the back of the house, a stone door entrance is revealed. The camera continues rotating to the other side. Throughout the entire rotation, the structure remains stationary, and the lighting stays consistent.
Example 7
The magical double-bladed axe combines practicality and decoration. Its T-shaped structure features sharp dual arc blades at the top, with a deep gray metallic surface that has fine textures and geometric patterns. The central sturdy support exudes a regal aura, while the deep wood-colored axe handle wrapped in red and black textured rope enhances grip. The extended bottom provides a balanced feel, and the exquisite design makes it an art collectible.
The video is filmed from a straight-on perspective, starting from the side of the axe. As the axe rotates, viewers gradually see the top of the axe and the detailed textures of the blade. As the rotation continues, the red wrapping decoration on the handle becomes fully visible, showcasing the grip details of the axe. When the rotation reaches the front of the axe, the intricate geometric patterns on the central metal part can be seen—details that are not visible from other angles. Finally, the video completes a full 360-degree rotation of the axe, revealing its elegant yet deadly design.